This article highlights a few ideas from Hussein Nasser’s 31-hour-long Udemy course about database engineering.
Databases are general-purpose tools. They must handle significant complexity just to allow reliable reading and writing of data. Why is that? Because the client (the backend in this context) relies on the integrity of the data even though it sends multiple, possibly conflicting queries in a short amount of time. Also, some queries are linked and if one fails, the related queries should be undone. That is why transactions were introduced, which allow the grouping of queries and a mass rollback if necessary. There are four properties with which the database management system can guarantee the reliability of transactions. These are the ACID properties.
- A (Atomicity): this allows queries to be treated as one unit and either all succeed or none of them. For example thanks to atomicity, one can avoid decreasing one account while failing to increase another during a transfer. Without a transaction money or points can disappear into thin air. To be fair, one can check the result of previous steps and manually roll back. That is often the only viable option when the different queries cannot be put in one transaction. For example, because different microservices are responsible for the different steps.
- C (Consistency): this means state changes follow all the rules, so reading one aspect of the same information should be in sync with reading another. This is not always possible though. When databases have to scale, different sections can end up on different servers. This latter solution is called sharding and should be the last resort, because with sharding we lose the chance to rely on transactions. First, try to optimize the queries. If those cannot be improved, we can try to create replication tables. There we split the data horizontally and manage more than one table instead of one.
Eventual consistency should also be mentioned. It is the attitude that the accuracy of some information is not important enough to always be correct, but eventually the relevant updates are going to happen. For example, one can avoid to be 100% up-to-date with the number of likes. The summary statistics eventually can be in sync with the data of the join tables. - I (Isolation): Different degrees of isolation can protect against phenomena like:
- dirty read - when reading an uncommitted change, which later gets rolled back
- non-repeatable reads - when we read twice in a transaction, but the second read leads to a different result because of a new change which was committed
- lost updates - the last transaction to commit overwrites the changes made by earlier transaction(s), leading to data loss
- phantom reads - when a new insert changes the result of a sum which will no longer be in sync with a previous read.
- D (Durability): we expect that once we receive a successful commit response, the data will be available even if a crash occurs right after that response. The interesting part is that for that to be implemented it is not necessary that the changes get flushed to the pages (corresponding to sections of a table) stored in memory. It is enough if a log is saved based on which the changes can be applied on the pages stored on the disk. One implementation is the WAL (write ahead log) in Postgres, which stores the differences and periodically flushes them to disk. This moment is the checkpointing which requires some resources and can add to the variability of database response times.
There are five theoretical levels of isolation that can be implemented by a database and selected by the writer of the transaction.
- Read uncommitted - there is no isolation, the transaction “sees” all the changes, even the ones not committed.
- Read committed - only the committed changes are visible in a transaction
- Repeatable read - this makes sure that while a query reads a row, that row does not change
- Snapshot - the transaction “sees” only the result of transactions which were committed before the start of the given transaction (not just the target row is locked, so phantom reads can be avoided)
- Serializable - its effect is like transactions were run one after another - this protects from everything but it slows the processes down, so it is not the default choice.
It is worth noting that the theoretical description of an isolation level name is not necessarily in line with their implementation. For example, repeatable read in Postgres is basically a snapshot isolation. It is best to know the default isolation level of your database and change that based on the given use case. For example: read committed is the default in Postgres and repeatable read is the default in MySQL.
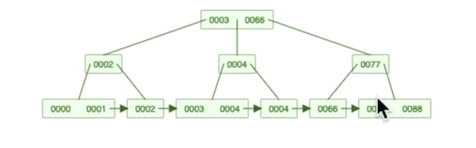
Another important database tool is indexing, which can improve the read time. An index is a data structure which allows data access in another way than the sequential read of the heap (data on the disk). It is usually a B+tree structure which allows the quick elimination of scenarios as we traverse down one of the branches of this tree. The leaves at the end either contain the requested row (index organized tables eg. MySQL index based on the primary key) or an identifier which points to the relevant page in the heap (tuple id in the case of Postgres). In the former case the secondary indexes point to the primary key, so two tree traversing is required which has to be kept in mind. The quickest is an index only scan, when the index is small enough to be kept in memory and no data is required which is not part of the index. However, keep in mind, that if the table is too big, even the index needs to be stored and requires I/Os to fetch even the indexed data. Creating indexes for everything is not the best strategy, because an update can slow down the response, since not only a row in the heap, but all the relevant indexes should be updated.