Ez a cikk Hussein Nasser 31 órás, adatbázis-tervezésről szóló Udemy kurzusának néhány fő gondolatát emeli ki.
Az adatbázisok általános célú eszközök. Jelentős komplexitást kell kezelniük ahhoz, hogy megbízhatóan olvassák és írják az adatokat. Miért van ez így? Mert a kliens (ebben az összefüggésben a backend) az adatok integritására támaszkodik, még akkor is, ha rövid idő alatt több, esetleg ütköző lekérdezést küld. Ezenkívül egyes lekérdezések össze vannak kapcsolva, és ha az egyik sikertelen, a kapcsolódó lekérdezések hatásait vissza kell vonni. Ezért vezették be a tranzakciókat, amelyek lehetővé teszik a lekérdezések csoportosítását és szükség esetén a tömeges visszavonást. Négy tulajdonsággal garantálhatja az adatbázis-kezelő rendszer a tranzakciók megbízhatóságát.
Ezek az ACID tulajdonságok.
-
A (Atomicity - Atomikusság): ez lehetővé teszi a lekérdezések egyetlen egységként való kezelését, és vagy mindegyik sikeres lesz, vagy egyik sem. Például az atomicitásnak köszönhetően elkerülhető, hogy egy átutalás során az egyik számla értéke csökkenjen, miközben egy másik értéke nem nő. Tranzakció nélkül adott esetben a pénz eltűnhetne a semmibe. Az igazsághoz hozzátartozik, hogy az is megoldás, hogy ellenőrizzük az előző lépések eredményét, és manuálisan visszaállítunk mindent, ha valami nem sikerült. Ez gyakran az egyetlen járható út, ha a különböző lekérdezéseket nem lehet tranzakcióba helyezni. Például azért, mert különböző microservice-k felelősek a különböző lépésekért, melyek más-más adatbázist használnak.
-
C (Consistency - Konzisztencia): ez azt jelenti, hogy az állapotváltozások minden szabályt követnek, így ugyanazon információ különböző előfordulásai szinkronban kell legyenek (pl hány sor eladás van és mit mutat egy statisztika, ami más oszlopban van tárolva). Ez azonban nem mindig lehetséges. Amikor az adatbázisoknak skálázniuk kell, a különböző részek különböző szerverekre kerülhetnek. Ez utóbbit shardingnak nevezik. Az oktatóanyag szerzője szerint ez legyen a végső megoldás, mert a shardinggal elveszítjük a tranzakciókra való támaszkodás lehetőségét. Először is próbáljuk meg optimalizálni a lekérdezéseket. Ha ezek nem javíthatók tovább, megpróbálhatunk replikációs táblákat létrehozni, ahol vízszintesen osztjuk fel a táblázatokat, és egynél több táblát kezelünk ugyanabból a struktúrából.
A késleltetett konzisztenciát is meg kell említeni. Ez azt a hozzáállást jelenti, hogy bizonyos adatok pontossága nem elég fontos ahhoz, hogy mindig helyesek legyenek, de végül a releváns frissítések megtörténnek. Például a külön tárolt like-ok összege nem tükrözi a kapcsolt tábla tényleges hosszát. Az összesített statisztikák azonban végül szinkronba kerülhetnek a kapcsolt táblák adataival. -
I (Isolation - Izoláció): Az izoláció különböző fokozatai védelmet nyújthatnak az olyan jelenségek ellen, mint:
- piszkos olvasás - amikor egy nem véglegesített módosítást olvasunk, amelyet később visszavonunk
- nem ismételhető olvasások - amikor egy tranzakcióban kétszer olvasunk, de a második olvasás más eredményhez vezet egy új véglegesített módosítás miatt
- elveszett frissítések - az utolsó véglegesített tranzakció felülírja a korábbi tranzakció(k) által végrehajtott módosításokat, ami adatvesztéshez vezet
- fantom olvasások - amikor egy új beszúrás megváltoztatja egy összeg eredményét, amely már nem lesz szinkronban egy korábbi olvasással
-
D (Durability - Tartósság): azt várjuk, hogy miután sikeres véglegesítési választ kapunk, az adatok elérhetőek lesznek akkor is, ha közvetlenül a válasz után összeomlás történik. Az érdekes az, hogy ennek megvalósításához nem szükséges, hogy a változtatások a memóriában tárolt oldalakra (amelyek a tábla releváns sorait tartalmazzák) kerüljenek. Elég, ha egy naplófájl kerül mentésre, amely alapján a változtatások alkalmazhatók a lemezen tárolt oldalakon. Az egyik ilyen implementáció a Postgres WAL (write ahead log), amely tárolja a különbségeket, és rendszeresen lemezre írja azokat. A tényleges oldalak lemezen való frissítése a checkpointing, amely némi erőforrást igényel, és növelheti az adatbázis válaszidejének változékonyságát.
Az izolációnak öt elméleti szintje létezik, amelyeket egy adatbázis valósíthat meg, és amelyeket a tranzakció írója választhat ki.
- Nem mentett olvasás (Read uncommitted) - nincs izoláció, a tranzakció az összes változást „látja”, még azokat is, amelyek nincsenek véglegesítve.
- Mentett olvasás (Read committed) - csak a véglegesített változások láthatók a tranzakcióban.
- Ismételhető olvasás (repeatable read) - ez biztosítja, hogy miközben egy lekérdezés beolvas egy sort, az a sor ne változzon.
- Pillanatfelvétel (snapshot) - a tranzakció csak azoknak a tranzakcióknak az eredményét „látja”, amelyek az adott tranzakció kezdete előtt véglegesítettek (nem csak a célsor van zárolva, így elkerülhetők a fantomolvasások).
- Szerializálható (Serializable) - hatása olyan, mintha a tranzakciók egymás után futnának - ez mindentől véd, de lelassítja a folyamatokat, így nem ez az alapértelmezett választás.
Érdemes megjegyezni, hogy az izolációs szint nevének elméleti leírása nem feltétlenül van összhangban a megvalósításukkal.
Például a Postgresben az ismételhető olvasás alapvetően egy pillanatfelvétel-izoláció. A legjobb, ha ismerjük az adatbázis alapértelmezett izolációs szintjét, és az adott használati eset alapján módosítjuk azt. Például: a Postgresben az alapértelmezett az “read committed”, a MySQL-ben pedig a “repeatable read”.
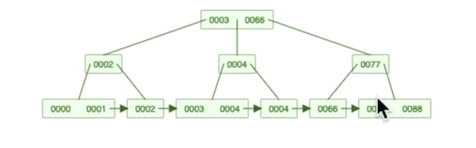
Egy másik fontos adatbázis-eszköz az indexelés, amely javíthatja az olvasási időt. Az index egy olyan adatstruktúra, amely lehetővé teszi az adatok elérését a heap (a lemezen lévő adatok) szekvenciális olvasásától eltérő módon. Általában egy B+fa struktúra, amely lehetővé teszi forgatókönyvek gyors kiküszöbölését, miközben a fa egyik ágán haladunk lefelé. A végén lévő levelek vagy a kért sort tartalmazzák (indexelt szervezett táblák, pl. MySQL index az elsődleges kulcs alapján), vagy egy azonosítót, amely a heap megfelelő oldalára mutat (tuple azonosító Postgres esetén). Az előbbi esetben a másodlagos indexek az elsődleges kulcsra mutatnak, tehát két fa bejárására van szükség, amit szem előtt kell tartani. A leggyorsabb az indexbeolvasás, amikor az index elég kicsi ahhoz, hogy a memóriában tárolható legyen, és nincs szükség olyan adatokra, amelyek nem részei az indexnek. Azonban ne feledjük, hogy ha a tábla túl nagy, akkor még az indexet is tárolni kell, és I/O műveletekre van szükség az indexelt adatok lekéréséhez is. Nem a legjobb stratégia minden elemhez indexet létrehozni, hiszen egy frissítés lelassíthatja a választ, mivel nemcsak a tábla egy sorát, hanem az összes releváns indexet frissíteni kell.